Research
Research is the place to do occasional deep work on one instrument: study how it behaves, look for an edge, and turn what you find into a playbook, an instrument profile, or preparation notes. By the end of this page you’ll know how a workspace and its runs are organised, when to turn on guardrails, and how to hand a finished run to the Copilot.
What this is
Section titled “What this is”A research workspace belongs to exactly one symbol. Inside it you start research runs — deep AI passes over that instrument that read MT5 candles from D1, H4, H1, and M15 and produce markdown-first output. The symbol is validated against your default MT5 account’s catalog when the workspace is created and again when a run starts, so a typo or an unknown symbol is rejected with suggestions rather than silently producing nothing.
Cortiq owns the research prompt. Anything you type is additional instruction layered on top of Cortiq’s framing, treated as untrusted notes — it cannot override the research rules, the validation logic, or the guardrails.
Each completed run writes an artifact bundle to disk: report.md for the summary, one candles_<timeframe>.parquet file per timeframe, and a meta.json. A file-capable agent can open these directly. The database stays the source of truth — a failed disk write is logged and never fails the run.
How it fits into Cortiq
Section titled “How it fits into Cortiq”Research is upstream of the trading cycle. A session trades; research is where the thinking that shapes a session happens, then feeds back in as a playbook, a profile, or preparation context.
| Surface | Cadence | Produces |
|---|---|---|
| Research | Occasional, deep | Findings, edge tests, drafts you hand off |
| Playbooks & data | Per strategy | The rules a session executes |
| Sessions | Continuous | Live or simulated trading |
The workspace presents itself as a single-instrument analyst station. The detail page reads as a guided “what’s next” experience: a soft three-stage strip at the top, a results-first card for the selected run, and a single collapsible Details disclosure that holds everything advanced.
How to use it
Section titled “How to use it”1. Create a workspace for one symbol
Section titled “1. Create a workspace for one symbol”Open Preparation → Research, or navigate to /research. The list shows your workspaces, each scoped to one instrument.
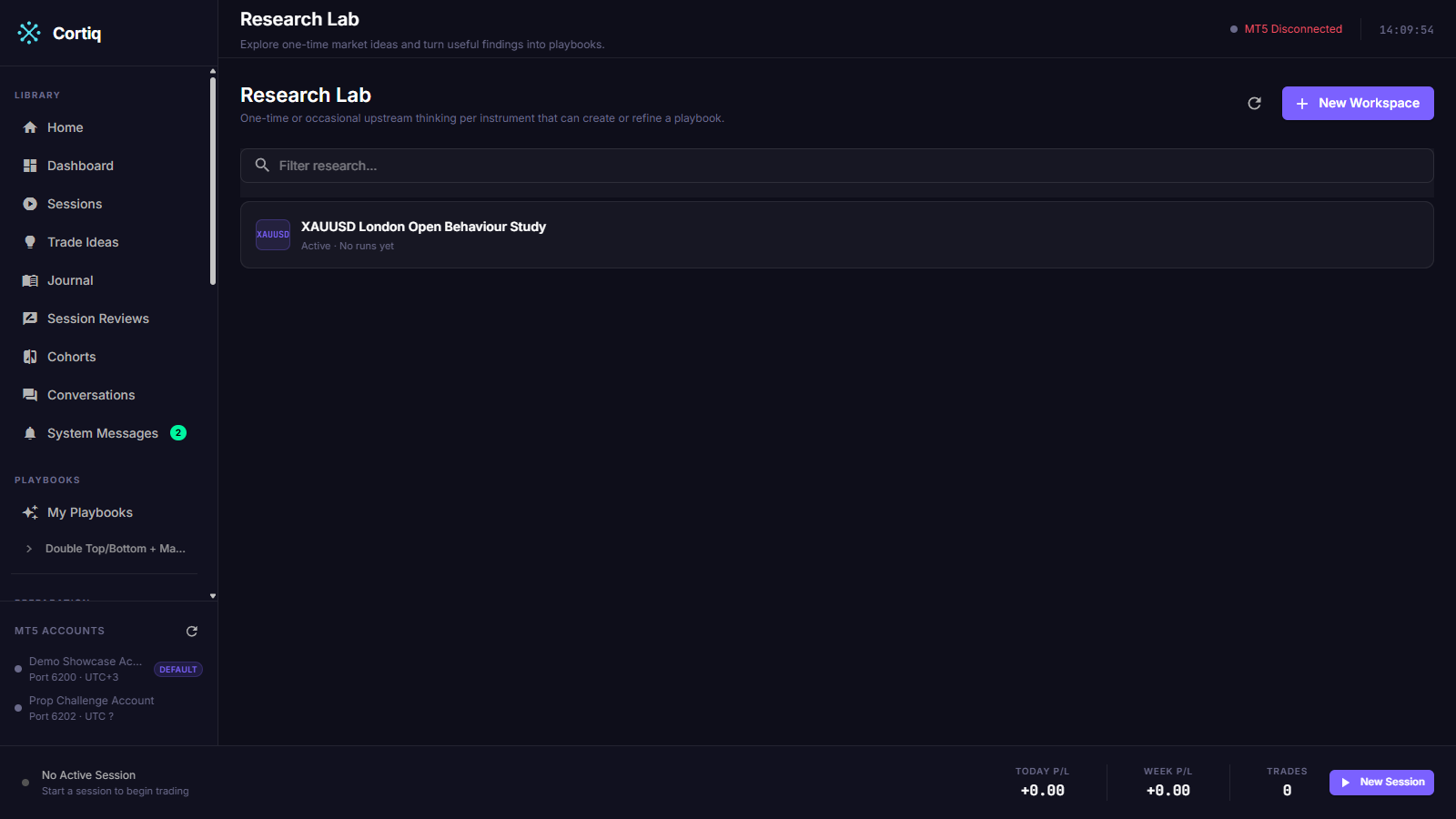
Select New (/research/new) and enter or pick the symbol. The header of a workspace shows its run and snapshot counts and the downstream approval state.
2. Follow the three-stage strip
Section titled “2. Follow the three-stage strip”The detail page opens with a soft pipeline strip: Understand behaviour → Find an edge → Build a playbook. Each stage is marked done, now, or next, derived from the workspace’s runs — there is no saved stage state. The strip is a signpost, not a gate: click any stage to start that kind of run and jump straight there.
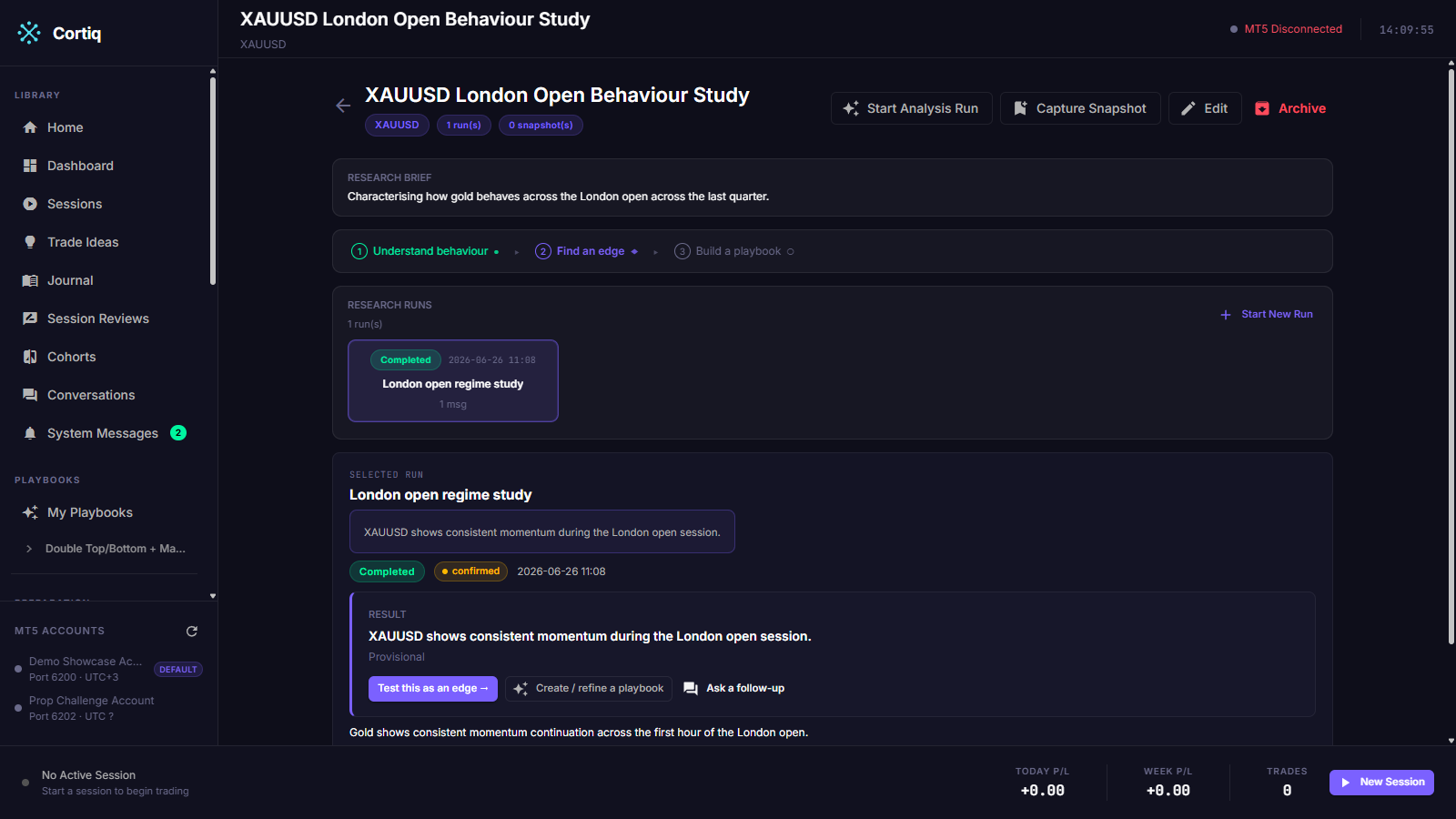
The results card leads with the answer: the run’s headline and a plain-language confidence line (Confirmed / Provisional / Needs more data / Did not hold up), followed by exactly one primary button — the recommended next step. Secondary one-click actions sit alongside: Create/refine a playbook and Ask a follow-up.
3. Run free, or add guardrails
Section titled “3. Run free, or add guardrails”By default a run is free research — no constraints. To pin a run down, toggle Add guardrails (optional), which reveals preset pickers only (no hand-typed format strings):
- Session — Whole day, London open, NY open, Asia, or Custom.
- Risk — 1R stop-target, ATR stop, or Custom.
- Setup — Any, or a named setup family.
- Require at least N examples — a minimum sample size.
A preset left at its non-narrowing value (Whole day, Any, blank) is omitted entirely, so the frozen guardrail record holds only the lines you actually narrowed. An Advanced sub-section sets the honest-test hold-back percentage.
With guardrails on, the run executes as three sequential phases in one research session — freeze the locked constraints and propose train-only hypotheses, then build the scoring and threshold plan, then run the chronological honest test and draft a playbook or rejected ideas. Each phase is persisted as a message tied to the run.
4. Hand a finished run to the Copilot
Section titled “4. Hand a finished run to the Copilot”A completed run with artifacts exposes three affordances:
- Open report — reveals
report.mdin your file explorer. - Open data folder — reveals the run’s artifact folder.
- Use this research → — seeds the Copilot with the run’s summary and findings inline, names the saved file paths, and asks which downstream asset to create or update: a Playbook, an Instrument Profile, or Preparation notes. The Copilot drives the chosen path through its MCP tools and the approval gate; preparation notes land in
prep-notes.mdin the run’s folder.
Reference
Section titled “Reference”On-disk artifact bundle
Section titled “On-disk artifact bundle”| File | Contents |
|---|---|
report.md | The run’s markdown summary and output. |
candles_<timeframe>.parquet | Raw MT5 candles per timeframe (D1, H4, H1, M15). |
meta.json | Symbol, workspace ID, run ID, timestamps, model name. |
prep-notes.md | Written when a hand-off creates preparation notes. |
The folder lives under AppData at research/<symbol>/<workspaceId>-<slug>/run-<runId>/. The path is stored on the run; a null path means no artifacts were written yet.
Plain-language verdicts
Section titled “Plain-language verdicts”| Engine concept | Shown as |
|---|---|
| Out-of-sample status | Honest-test verdict (Passed / Failed / Not enough examples / Needs review) |
| Lockbox sample | Examples |
| Expectancy | Avg result (R) |
| Readiness | Confirmed / Provisional / Did not hold up / Needs more data |
The UI deliberately avoids the words “OOS”, “out-of-sample”, and “lockbox”.
Current boundaries
Section titled “Current boundaries”- The deterministic edge-discovery engine is not yet built. Research asks the AI to reason over the structured prompt and supplied candles, and to mark untested ideas as hypotheses or insufficient sample.
- The data collector supplies multi-timeframe candle tables, not candidate tables, labels, or walk-forward outputs.
- Every follow-up run re-collects fresh MT5 data and applies the same loud guard: a run that expected candles but received none fails rather than fabricating output.
Common questions
Section titled “Common questions”I cleared the guardrail fields but a “locked to” record still showed before — why? That confusion is gone. A free-research run shows no lockbox record at all. The record renders only for runs that actually used guardrails.
Can my typed instructions override Cortiq’s research rules? No. Operator text is treated as untrusted notes. It cannot move the frozen guardrails, upgrade a hypothesis without evidence, or bypass the prompt and tool-use rules.
Why does a run take so long? Research calls allow a 30-minute request window to accommodate deep work over slower transports. A guardrailed run is three phases, so it takes longer than a single free run.
What to read next
Section titled “What to read next”- Skills — reusable instruction templates you can inject into a research run.
- Playbooks & data — the playbook a finished run can become.
- Session review — the other learning loop, after a session has traded.